Николай Малых
Для определения задержек вносимых при обработке пакетов в больших (десятки тысяч правил) таблицах iptables были проведены измерения на хосте Linux с ядром 2.6.10. Тестовый хост представлял собой embedded-платформу на базе процессора VIA с тактовой частотой 533 МГц. Во время тестирования нагрузка хоста была незначительной, т. е., не использовалось сильно нагружаюших процессор приложений. Уровень загрузки можно оценить по приведенным на рисунке 1 результатам top
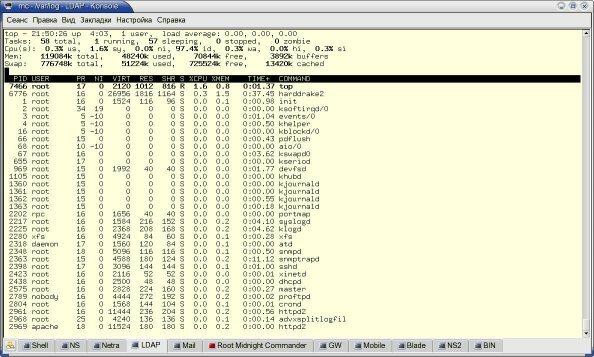
Рисунке 1: Уровень загрузки тестового хоста
Таблицы iptables были достаточно просты и представляли собой 1 правило в цепочке INPUT, которое передавало все пакеты UDP в пользовательскую цепочку Test
iptables -A INPUT -p udp -j Test
Пользовательская цепочка Test содержала 65535 правил в соответствии с номерами портов. Все правила, кроме последнего, в качестве действия указывали стандартную операцию ACCEPT (принять пакет), а последнее правило (для порта discard) задавало действие REJECT
iptables -A Test -p udp -m udp –-dport 0 -j ACCEPT
iptables -A Test -p udp -m udp –-dport 1 -j ACCEPT
iptables -A Test -p udp -m udp –-dport 2 -j ACCEPT
...
iptables -A Test -p udp -m udp –-dport discard -j REJECT –reject-with icmp-admin-prohiibited
такой набор правил позволял без особых сложностей определить время между приемом пакета от генератора и передачей отправителю сообщения ICMP о запрете доступа в порт. На тестовом хосте для сбора пакетов использовалась простая команда
tcpdump host 172.16.33.44 and \(udp port 9 or icmp)
которая позволяла записывать только нужные пакеты.
При запуске генератора на консоль тестового хоста выдавалась информация, подобная приведенной на рисунке 2. Первые тесты проводились с пакетами малого размера (100 байт), которые генерировались с достаточно низкой частотой (1 – 100 пакетов в секунду). После этого были проведены тесты на пакетах полного размера (1500 байт в кадре Ethernet), генерируемых с максимальной скоростью.
Прежде, чем перейти к вычислению задержек отметим, что генерация откликов ICMP происходит не для каждого отвергнутого пакета, как можно было бы предположить из логики работы правил iptables. Это отнюдь не говорит о том, что netfilter не справляется с задачами и пропускает часть пакетов, которые должны быть отвергнуты. Дабы убедиться в этом, достаточно вставить в набор правил две строки, первая из которых будет записывать в журнальный файл информацию о пакетах непосредственно перед правилом REJECT, а вторая – сразу после него. Если это проделать, то число записей в журнальном файле для пакетов перед строкой REJECT в точности соответствует числу переданных генератором пакетов, а после прохождения правила REJECT не остается ни одного пакета (т. е., правило корректно отбрасывает все пакеты). Объяснение же факту несовпадения числа принятых пакетов с числом переданных сообщений ICMP объясняется логикой работы протокола ICMP, который в соответствии со стандартом ограничивает частоту генерации сообщений unreachable для одного получателя. Ниже мы рассмотрим другой вариант теста, который подтверждает это.
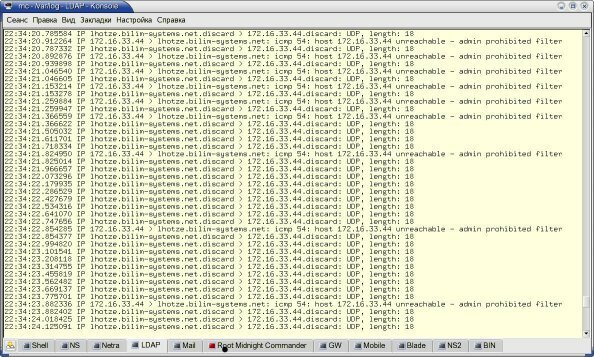
Рисунок 2: Результаты первого теста
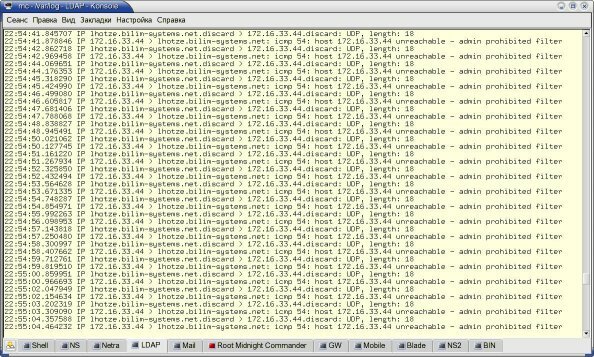
Рисунок 3: Результаты теста с малой скоростью доставки
Если же генерировать пакеты с максимально возможной скоростью возникает очень интересный эффект (см. рис. 4) – для первого пакета наблюдается нормальная задержка, а для последующих задержка падает до очень низких значений порядка 100 мксек на цепочку из 65535 правил (менее 2 нсек на правило). Трудно поверить, что решение о судьбе пакета может быть принято за время, равное одному машинному циклу (тактовая частота процессора составляет 533 МГц). Единственное объяснение, которое я нашел этому факту, – некий механизм кэширования, который используется в netfilter. Следующий эксперимент с разными адресами отправителя в пакетах является косвенным подтверждением этой догадки. Вернемся к задержке для первого пакета. После многократно проведенных тестов для пакетов максимального размера было получено среднее значение задержки 40 мсек на цепочку из 65535 правил или 600 нсек на одно правило.
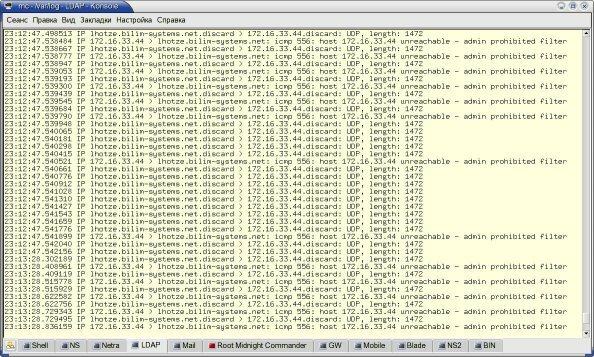
Рисунок 4: Результаты тестирования для больших пакетов при максимальной скорости
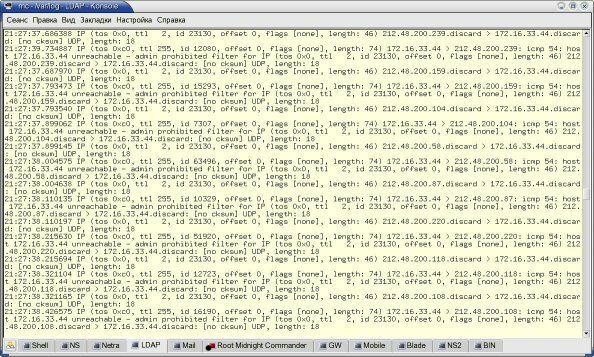
Рисунок 5: Результаты теста с различными адресами отправителя
В завершении я хочу привести результаты теста на реально используемом шлюзе с достаточно высоким уровнем трафика (на момент тестирования исходящий трафик составлял около 2 Мбит/с).
Для теста был выбран паразитный трафик SMTP (спам) из сети 218.0.0.0/8, который фильтруется на нашем граничном шлюзе. Правило для этой сети находится в самом конце цепочки, общая протяженность которой составляет около 14000 правил.
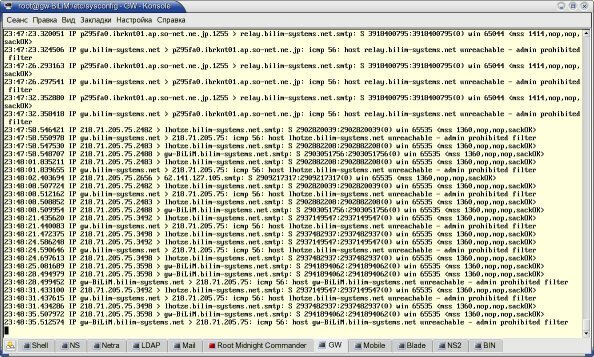
Рисунок 6: Результаты обработки пакетов на реальном шлюзе
В заключение несколько слов о рабочем шлюзе, для которого был приведен последний результат:
Celeron 300 МГц,
ОЗУ 512 Мбайт
Ядро 2.6.10
iptables 1.3.0 с дополнительными модулями, которые разработаны в нашей компании
Шлюз маршрутизирует трафик между 4 сегментами Ethernet/Fast Ethernet для автономной системы. Машрутизация организована на основе Zebra 0.94.
Дата обновления 07.02.2004